Can we train AI on our brand?
In the future all brand style guides will include links to the brand’s Textual Inversion concept library, so when you use AI art models to create new assets they’ll always be on brand.
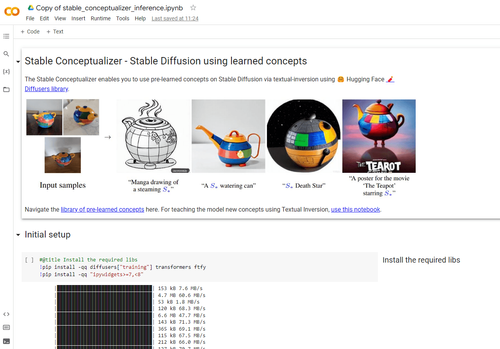
Textual Inversion
AI art models like DALL-E, Midjourney, and Stable Diffusion have trained on millions of images, but they don’t know every concept...More






Ok so let me get this right: Stable Diffusion is like an open source version of DALL-E?
And it has this functionality DALL-E doesn’t, Textual Inversion?
Alright and what that means is we can ‘train’ it on our brand, our products, etc and then we can use them later when generating creative assets for our ads?
Brilliant, this sounds promising, give it a whirl and report back.
This course is a work of fiction. Unless otherwise indicated, all the names, characters, businesses, data, places, events and incidents in this course are either the product of the author's imagination or used in a fictitious manner. Any resemblance to actual persons, living or dead, or actual events is purely coincidental.
AI models like DALL-E, Midjourney, and Stable Diffusion can ‘imagine’ almost any concept you can think of that’s in the public domain. They’ve trained on more images than any human artist could encounter in a lifetime, and they know how to draw all of them. However there are plenty of concepts that they don’t yet understand, and often these more niche concepts are the most important for business use cases. For example unless you’re Coca Cola, the popular AI models are unlikely to have seen many images of your brand or product in the training set. If you’re inventing something new it’ll definitely not be present in the models parameters. However there is a technique for ‘training’ the model to understand a specific concept you dictate. It’s called Textual Inversion, and so far it only works only on Stable Diffusion, the open source alternative to DALL-E. The process is that you upload 3 - 5 images of a concept – an object or style – and run the training script. That finds a space in the existing model that corresponds to the combination of features your sample images have, and then adds a label there, a token, so you’re able to reuse that pointer next time.
Say for example you wanted to add the concept of a specific product you were about to launch called the GoolyBib. You could upload 3 - 5 images and train the model for 1-4 hours on a GPU, a specialised graphics card suited to running ML models, and then that’s saved to a concepts library. Once you import the library you can reference that concept again using the token you designated, for example <goolybib>. Now in prompts you can say “<goolybib> photoshoot in high detail”, or “photo in street style of <goolybib>”, or “elon musk buying a <goolybib>”, whatever images you need to create. You can also train styles, so for example rather than training on your product, you could train on a consistent brand style, and use that in your images to make sure they’re recognizable and easier to get approval to use. This solves a key issue with AI models that have precluded them from being used by businesses in great numbers: you need consistency in order to make the images useful.
Complete all of the exercises first to receive your certificate!
Share This Course